-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
LLVM是C++编写的构架编译器的框架系统,可用于优化以任意程序语言编写的程序。
LLVM IR可以理解为LLVM平台的汇编语言,所以官方也是以语言参考手册(Language Reference Manual)的形式给出LLVM IR的文档说明。既然是汇编语言,那么就和传统的CUP类似,有特定的汇编指令集。但是它又与传统的特定平台相关的指令集(x86,ARM,RISC-V等)不一样,它定位为平台无关的汇编语言。也就是说,LLVM IR是一种相对于CUP指令集高级,但是又是一种低级的代码中间表示(比抽象语法树等高级表示更加低级)。
LLVM IR即代码的中间表示,有三种形式:
.ll 格式:人类可以阅读的文本(汇编码) -->这个就是我们要学习的IR
.bc 格式:适合机器存储的二进制文件
内存表示
下面给出.ll格式和.bc格式生成及相互转换的常用指令清单:
.c -> .ll:clang -emit-llvm -S a.c -o a.ll
.c -> .bc: clang -emit-llvm -c a.c -o a.bc
.ll -> .bc: llvm-as a.ll -o a.bc
.bc -> .ll: llvm-dis a.bc -o a.ll
.bc -> .s: llc a.bc -o a.s那么我们以一道CTF赛题来分析实验,学习LLVM IR
题目附件直接给出了中间表示.II文件

打开查看一下汇编码,毕竟.II文件是人类可以阅读的文本,这边笔者使用的是Sublime Text(使用VScode查看即可)代码量不多,大概600行
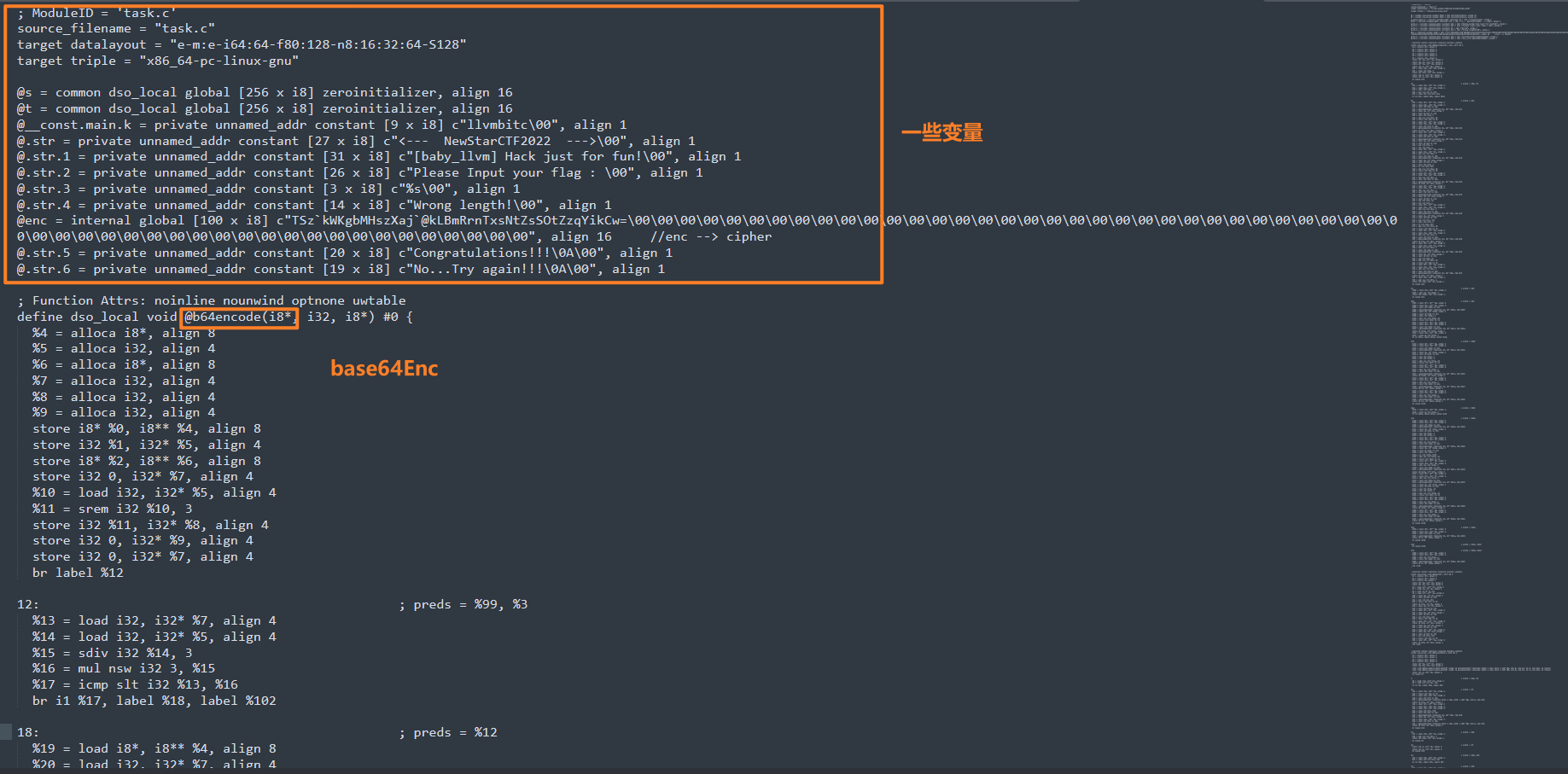
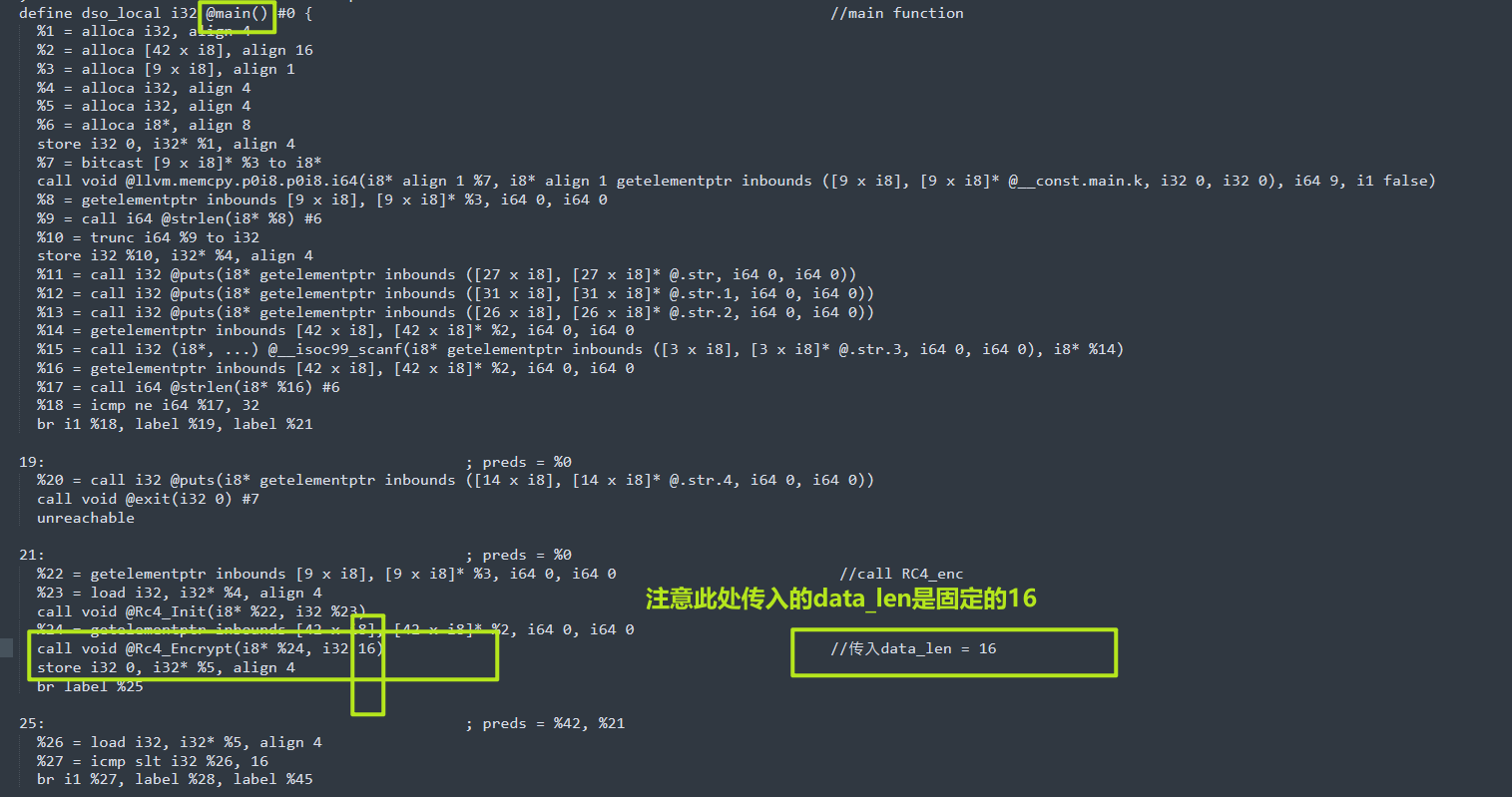
我们直接寻找一下main函数
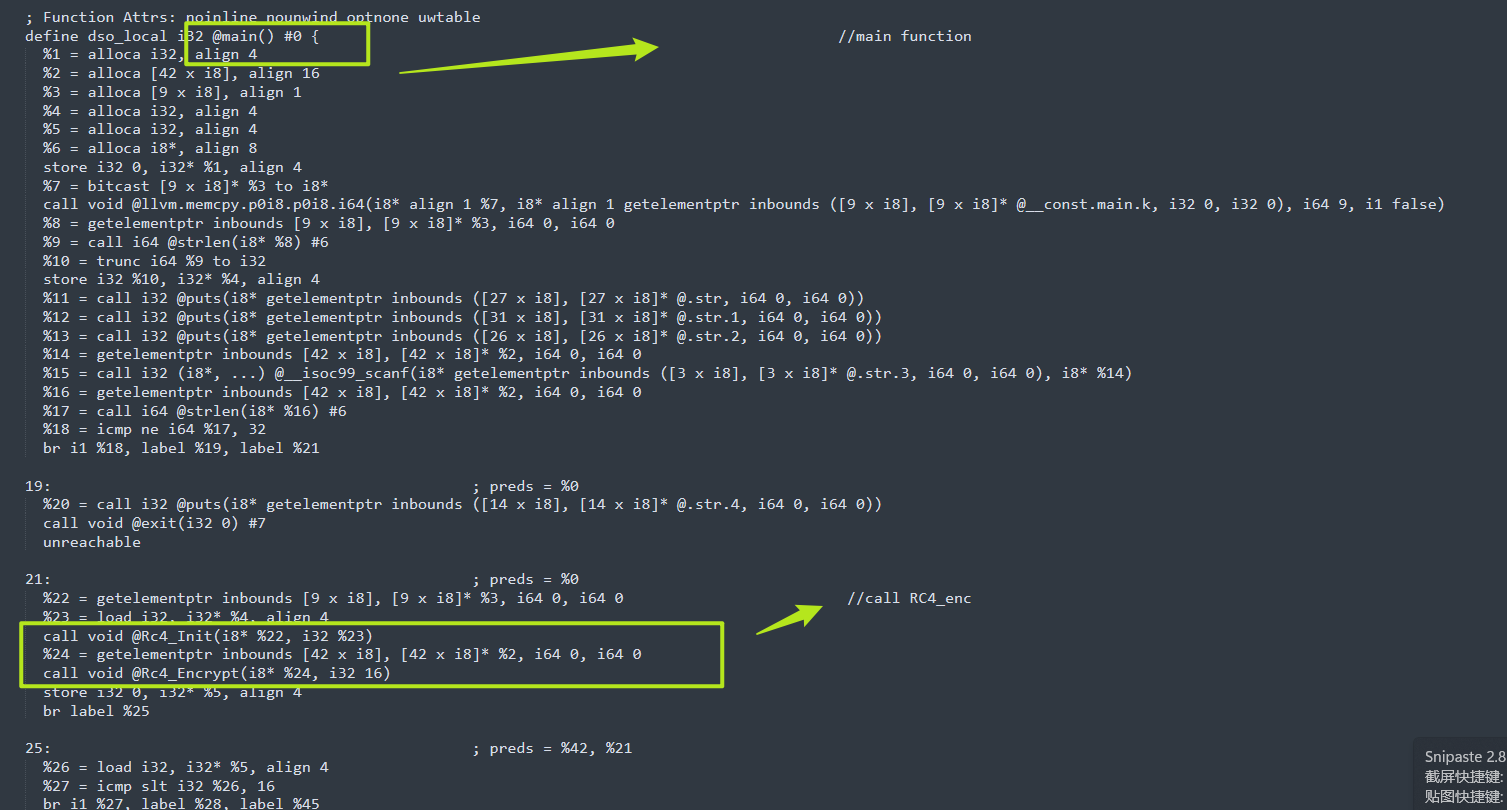
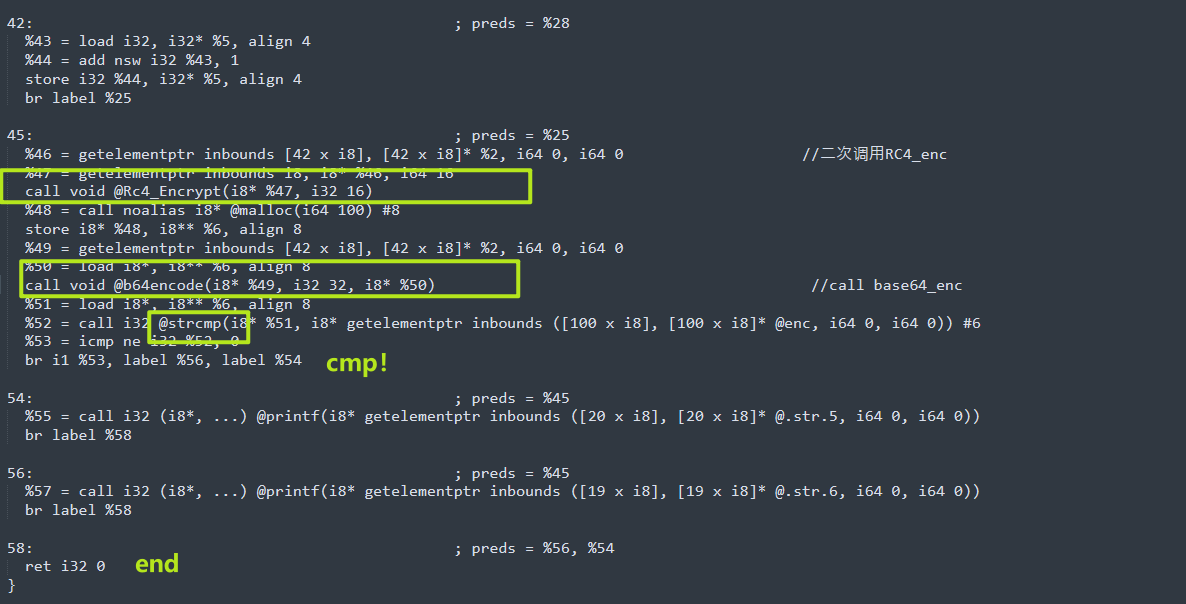
我们可以看出题目经历了两次RC4,然后Base64,我们从上面可以看到密文,RC4_key,我们直接一把锁,cyberchef启动,会发现解不出来,那么程序应该做了其他的操作,最朴素的,我们可以想到把RC4魔改了,base64魔改等等。
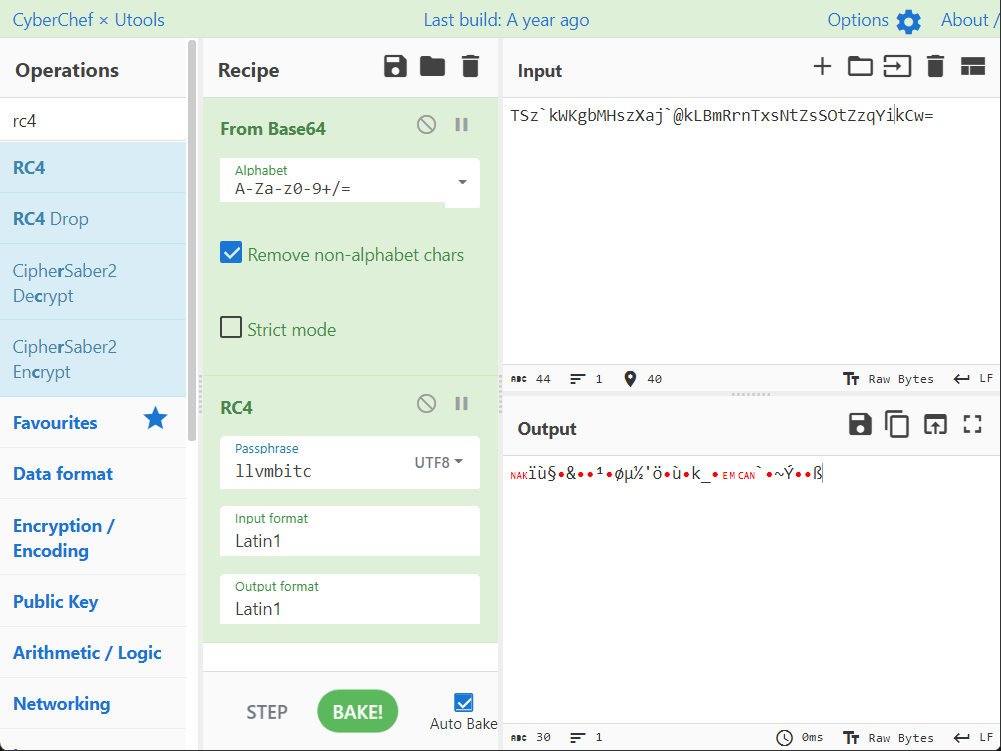
So!继续学习研究ing
所以本着学习的态度,我们这时候应该掏出LLVM Language Reference Manual(官方文档)来简单了解学习一些常见指令、符号标识以及特性。这边给出一些分析 .ll 中间文件的算法流程
@ - 全局变量
% - 局部变量
alloca - 在当前执行的函数的堆栈帧中分配内存,当该函数返回到其调用者时,将自动释放内存
i32 - 32位4字节的整数
align - 对齐
load - 读出,store写入
icmp - 两个整数值比较,返回布尔值
br - 选择分支,根据条件来转向label,不根据条件跳转的话类型goto
label - 代码标签
call - 调用函数
首先看到一些全局变量,知道了RC4_key = llvmbitccipher = "TSzkWKgbMHszXaj@kLBmRrnTxsNtZsSOtZzqYikCw="
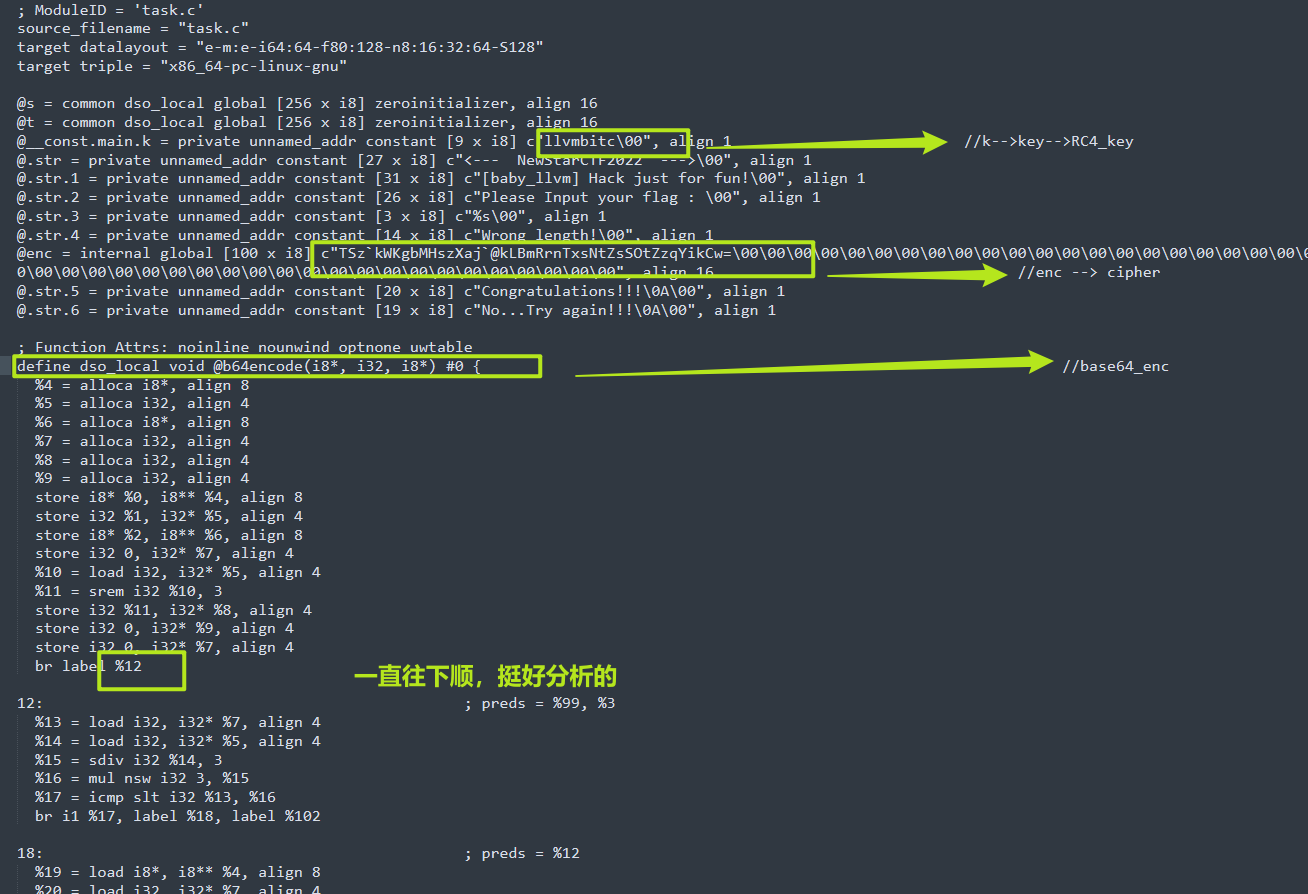
我们继续分析,重点分析各个function
b64encode 魔改
每三个字符,24位,切分成4断,每段6位。
将6位对应的值 (value+ 59)&0xff 则是编码后的值。
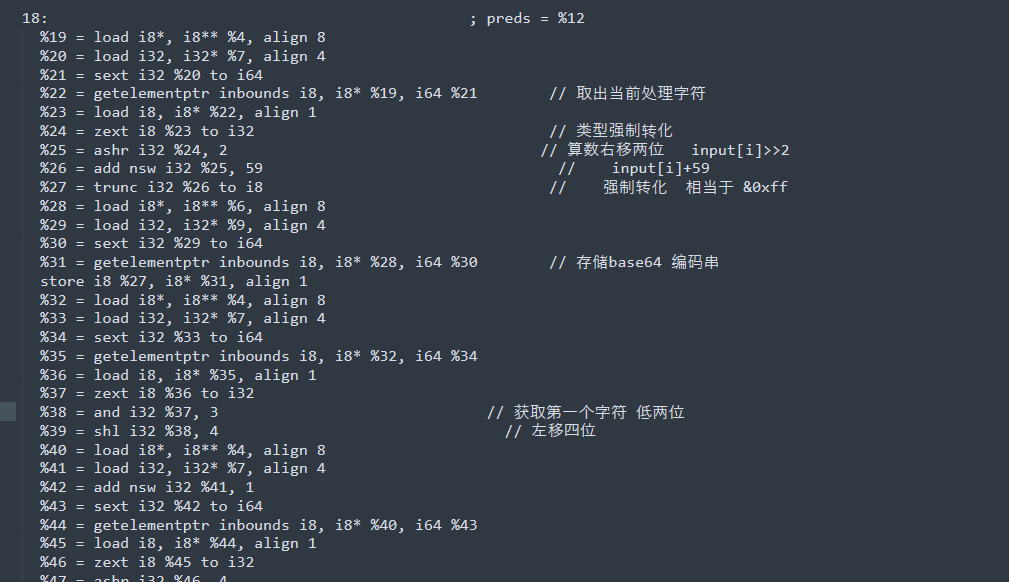
%22 = getelementptr inbounds i8, i8* %19, i64 %21 // 取出当前处理字符
%23 = load i8, i8* %22, align 1
%24 = zext i8 %23 to i32 // 类型强制转化
%25 = ashr i32 %24, 2 // 算数右移两位 input[i]>>2
%26 = add nsw i32 %25, 59 // input[i]+59
%27 = trunc i32 %26 to i8 // 强制转化 相当于 &0xff
%28 = load i8*, i8** %6, align 8
%29 = load i32, i32* %9, align 4
%30 = sext i32 %29 to i64
%31 = getelementptr inbounds i8, i8* %28, i64 %30 // 存储base64 编码串
store i8 %27, i8* %31, align 1
%32 = load i8*, i8** %4, align 8
%33 = load i32, i32* %7, align 4
%34 = sext i32 %33 to i64
%35 = getelementptr inbounds i8, i8* %32, i64 %34
%36 = load i8, i8* %35, align 1
%37 = zext i8 %36 to i32
%38 = and i32 %37, 3 // 获取第一个字符 低两位
%39 = shl i32 %38, 4 // 左移四位RC4_init 正常,无魔改
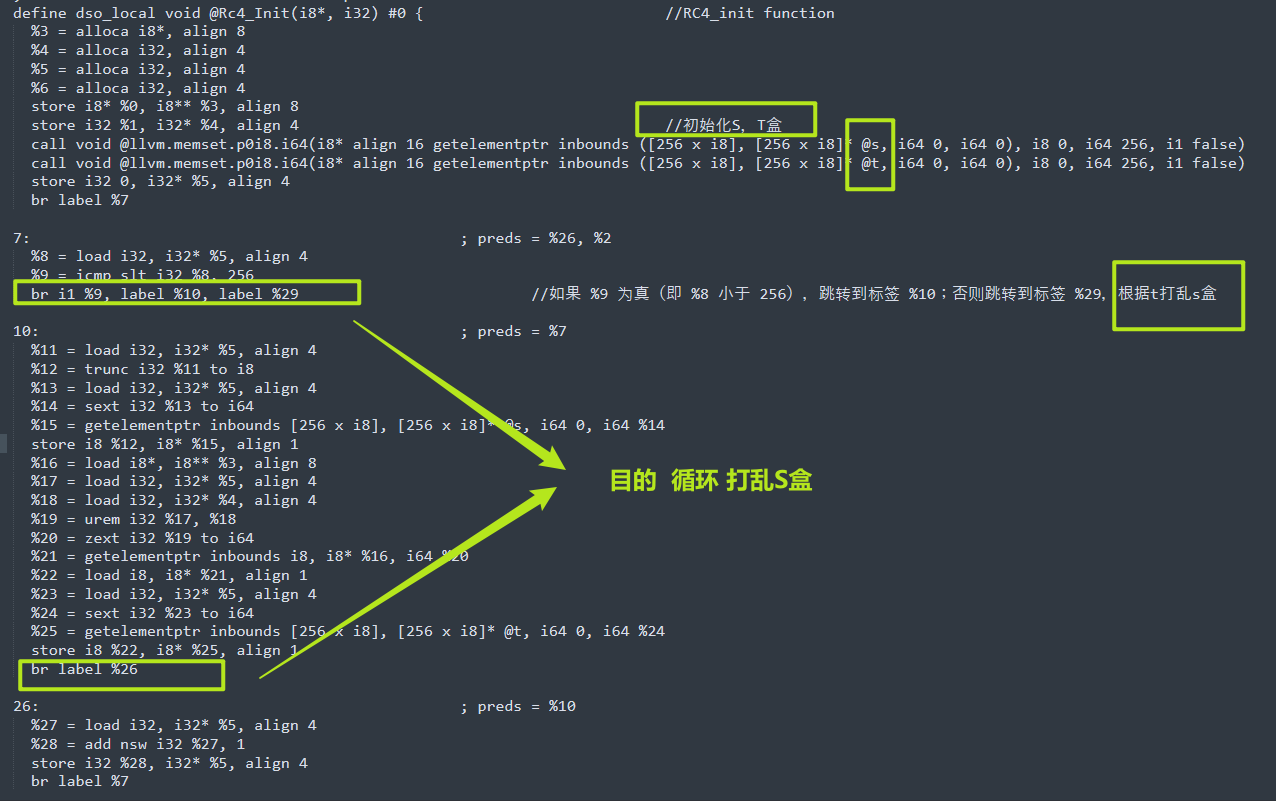
define dso_local void @Rc4_Init(i8*, i32) #0 { //RC4_init function
%3 = alloca i8*, align 8
%4 = alloca i32, align 4
%5 = alloca i32, align 4
%6 = alloca i32, align 4
store i8* %0, i8** %3, align 8
store i32 %1, i32* %4, align 4 //初始化S,T盒
call void @llvm.memset.p0i8.i64(i8* align 16 getelementptr inbounds ([256 x i8], [256 x i8]* @s, i64 0, i64 0), i8 0, i64 256, i1 false)
call void @llvm.memset.p0i8.i64(i8* align 16 getelementptr inbounds ([256 x i8], [256 x i8]* @t, i64 0, i64 0), i8 0, i64 256, i1 false)
store i32 0, i32* %5, align 4
br label %7
7: ; preds = %26, %2
%8 = load i32, i32* %5, align 4
%9 = icmp slt i32 %8, 256
br i1 %9, label %10, label %29 //如果 %9 为真(即 %8 小于 256),跳转到标签 %10;否则跳转到标签 %29,根据t打乱s盒
10: ; preds = %7
%11 = load i32, i32* %5, align 4
%12 = trunc i32 %11 to i8
%13 = load i32, i32* %5, align 4
%14 = sext i32 %13 to i64
%15 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %14
store i8 %12, i8* %15, align 1
%16 = load i8*, i8** %3, align 8
%17 = load i32, i32* %5, align 4
%18 = load i32, i32* %4, align 4
%19 = urem i32 %17, %18
%20 = zext i32 %19 to i64
%21 = getelementptr inbounds i8, i8* %16, i64 %20
%22 = load i8, i8* %21, align 1
%23 = load i32, i32* %5, align 4
%24 = sext i32 %23 to i64
%25 = getelementptr inbounds [256 x i8], [256 x i8]* @t, i64 0, i64 %24
store i8 %22, i8* %25, align 1
br label %26
26: ; preds = %10
%27 = load i32, i32* %5, align 4
%28 = add nsw i32 %27, 1
store i32 %28, i32* %5, align 4
br label %7
29: ; preds = %7
store i32 0, i32* %6, align 4
store i32 0, i32* %5, align 4
br label %30
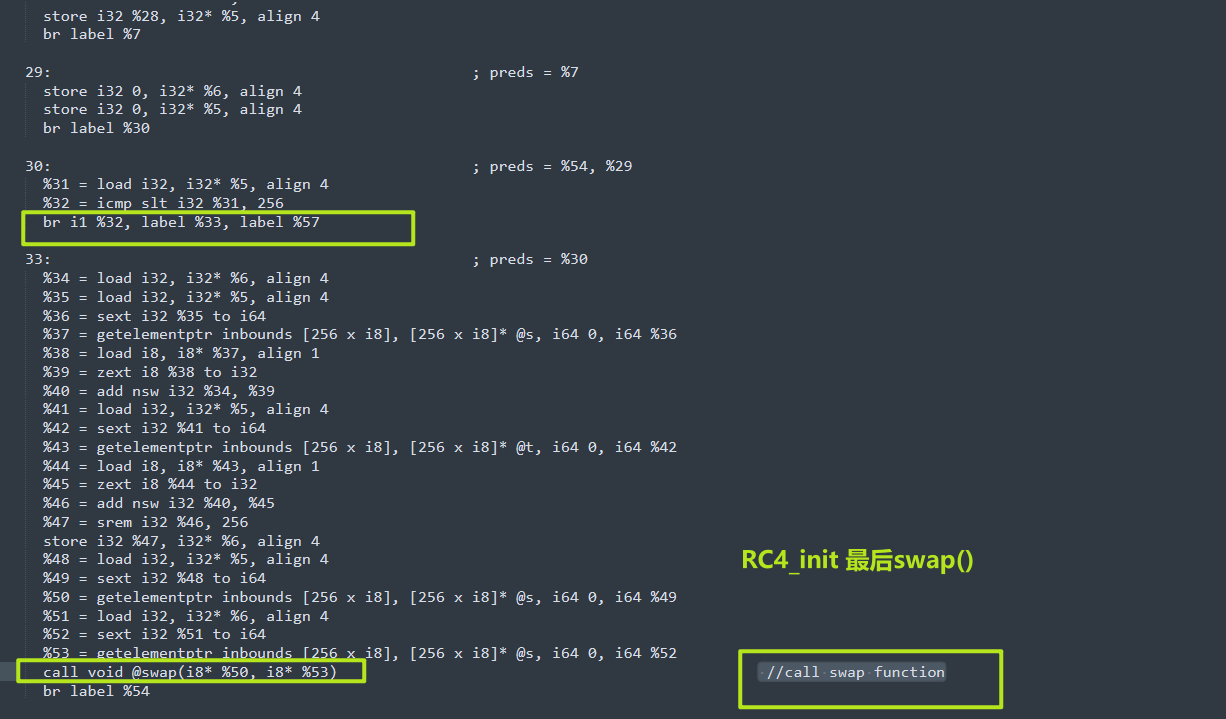
30: ; preds = %54, %29
%31 = load i32, i32* %5, align 4
%32 = icmp slt i32 %31, 256
br i1 %32, label %33, label %57
33: ; preds = %30
%34 = load i32, i32* %6, align 4
%35 = load i32, i32* %5, align 4
%36 = sext i32 %35 to i64
%37 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %36
%38 = load i8, i8* %37, align 1
%39 = zext i8 %38 to i32
%40 = add nsw i32 %34, %39
%41 = load i32, i32* %5, align 4
%42 = sext i32 %41 to i64
%43 = getelementptr inbounds [256 x i8], [256 x i8]* @t, i64 0, i64 %42
%44 = load i8, i8* %43, align 1
%45 = zext i8 %44 to i32
%46 = add nsw i32 %40, %45
%47 = srem i32 %46, 256
store i32 %47, i32* %6, align 4
%48 = load i32, i32* %5, align 4
%49 = sext i32 %48 to i64
%50 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %49
%51 = load i32, i32* %6, align 4
%52 = sext i32 %51 to i64
%53 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %52
call void @swap(i8* %50, i8* %53) //call swap function
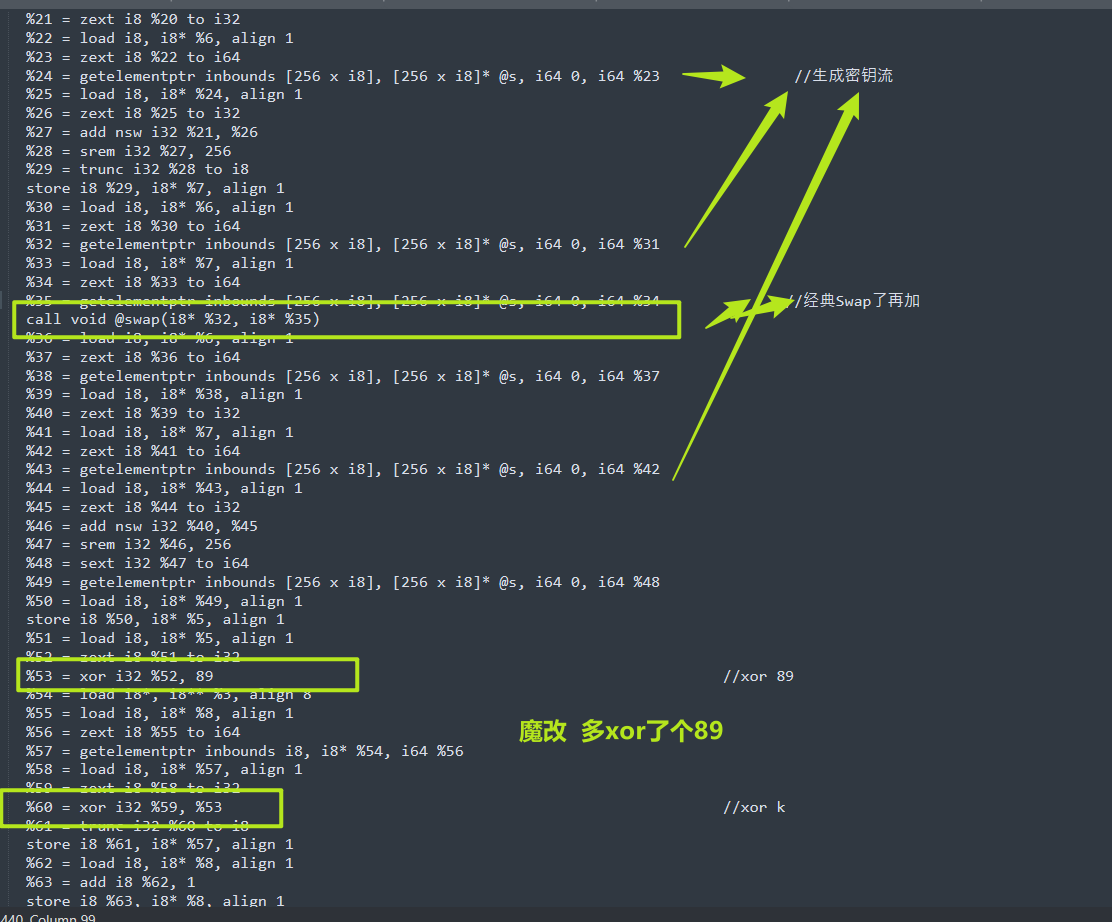
br label %54RC4_enc 魔改 多了一层xor 89
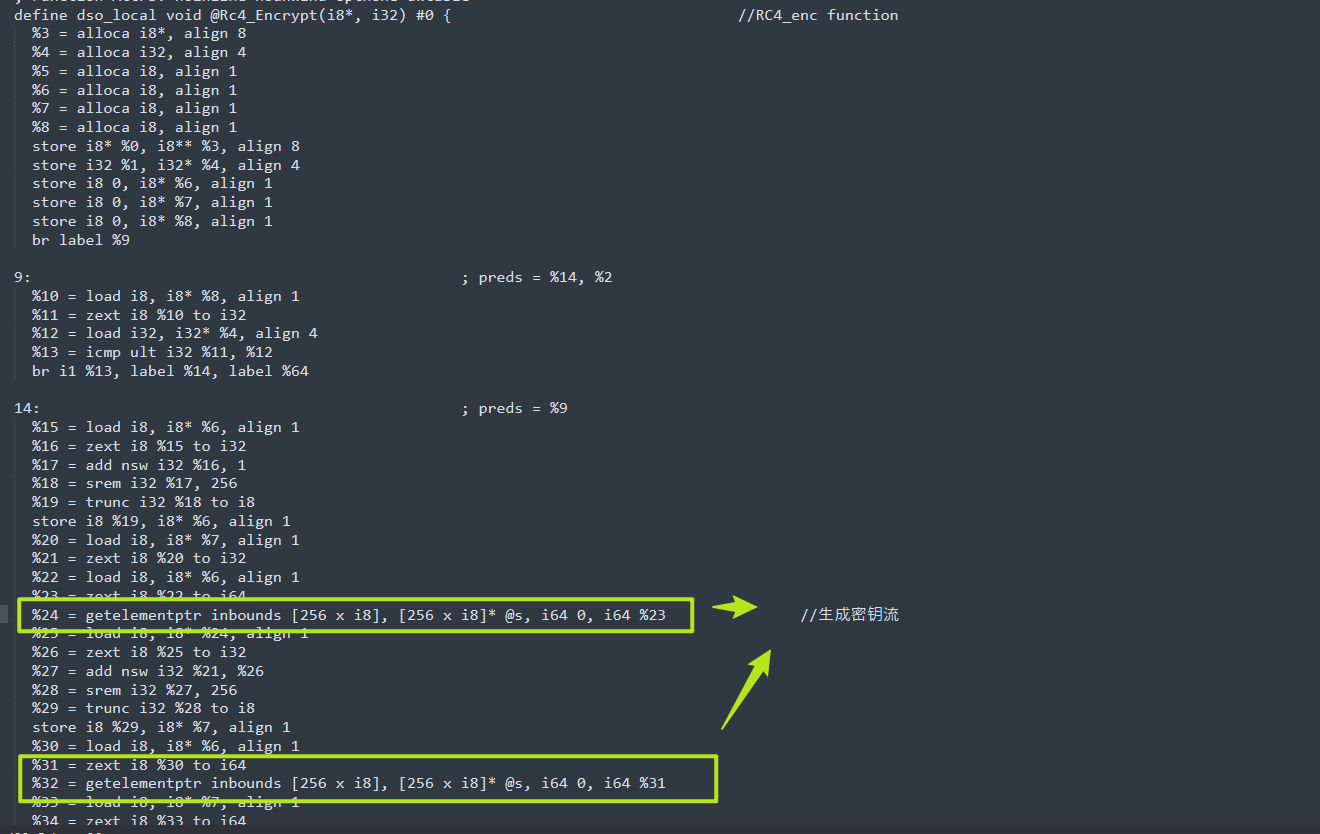
define dso_local void @Rc4_Encrypt(i8*, i32) #0 { //RC4_enc function
%3 = alloca i8*, align 8
%4 = alloca i32, align 4
%5 = alloca i8, align 1
%6 = alloca i8, align 1
%7 = alloca i8, align 1
%8 = alloca i8, align 1
store i8* %0, i8** %3, align 8
store i32 %1, i32* %4, align 4
store i8 0, i8* %6, align 1
store i8 0, i8* %7, align 1
store i8 0, i8* %8, align 1
br label %9
9: ; preds = %14, %2
%10 = load i8, i8* %8, align 1
%11 = zext i8 %10 to i32
%12 = load i32, i32* %4, align 4
%13 = icmp ult i32 %11, %12
br i1 %13, label %14, label %64
14: ; preds = %9
%15 = load i8, i8* %6, align 1
%16 = zext i8 %15 to i32
%17 = add nsw i32 %16, 1
%18 = srem i32 %17, 256
%19 = trunc i32 %18 to i8
store i8 %19, i8* %6, align 1
%20 = load i8, i8* %7, align 1
%21 = zext i8 %20 to i32
%22 = load i8, i8* %6, align 1
%23 = zext i8 %22 to i64
%24 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %23 //生成密钥流
%25 = load i8, i8* %24, align 1
%26 = zext i8 %25 to i32
%27 = add nsw i32 %21, %26
%28 = srem i32 %27, 256
%29 = trunc i32 %28 to i8
store i8 %29, i8* %7, align 1
%30 = load i8, i8* %6, align 1
%31 = zext i8 %30 to i64
%32 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %31
%33 = load i8, i8* %7, align 1
%34 = zext i8 %33 to i64
%35 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %34 //经典Swap了再加
call void @swap(i8* %32, i8* %35)
%36 = load i8, i8* %6, align 1
%37 = zext i8 %36 to i64
%38 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %37
%39 = load i8, i8* %38, align 1
%40 = zext i8 %39 to i32
%41 = load i8, i8* %7, align 1
%42 = zext i8 %41 to i64
%43 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %42
%44 = load i8, i8* %43, align 1
%45 = zext i8 %44 to i32
%46 = add nsw i32 %40, %45
%47 = srem i32 %46, 256
%48 = sext i32 %47 to i64
%49 = getelementptr inbounds [256 x i8], [256 x i8]* @s, i64 0, i64 %48
%50 = load i8, i8* %49, align 1
store i8 %50, i8* %5, align 1
%51 = load i8, i8* %5, align 1
%52 = zext i8 %51 to i32
%53 = xor i32 %52, 89 //xor 89
%54 = load i8*, i8** %3, align 8
%55 = load i8, i8* %8, align 1
%56 = zext i8 %55 to i64
%57 = getelementptr inbounds i8, i8* %54, i64 %56
%58 = load i8, i8* %57, align 1
%59 = zext i8 %58 to i32
%60 = xor i32 %59, %53 //xor k
%61 = trunc i32 %60 to i8
store i8 %61, i8* %57, align 1
%62 = load i8, i8* %8, align 1
%63 = add i8 %62, 1
store i8 %63, i8* %8, align 1
br label %9
64: ; preds = %9
ret void
}main函数逻辑cipher -->RC4_init-->RC4_enc-->RC4_enc-->b64encode需要注意一下在RC4_enc的参数中,传入的数据块长度是固定的16,所以说程序进行两次RC4_enc的原因也就确定了,是为了分两次对程序进行加密,也算是一点点小手段,总之,即使让你好好分析.II代码,考察对软件分析的细节,耐心,嘻嘻。
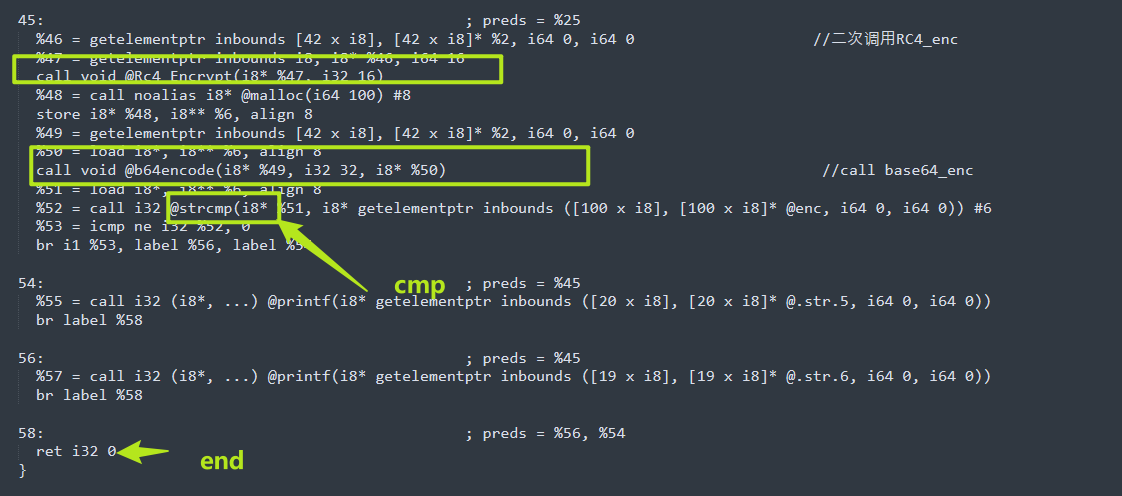
OK,理清楚逻辑,就可以试着敲代码解密啦。
逆向分析过程明了之后,那么写代码就简单多了
unsigned char s[300],t[300];
void b64decode(unsigned char * enc,unsigned char* dec);
void Rc4_dec1(int len, unsigned char *enc);
void Rc4_Init(char *key,int len);
void Rc4_dec2(int len, unsigned char *enc);
int main() {
unsigned char enc[50]="TSz`kWKgbMHszXaj`@kLBmRrnTxsNtZsSOtZzqYikCw=";
unsigned char dec1[50]={0x00};
char key[10] ="llvmbitc";
unsigned char a[50];
int i=0;
b64decode(enc,dec1);
Rc4_Init(key,8);
Rc4_dec1(16,&dec1[16]);
for(i=0;i<16;i++) {
dec1[i+16]^=dec1[i];
}
Rc4_Init(key,8);
Rc4_dec2(16,dec1);
printf("%s",dec1);
return 0;
}
void b64decode(unsigned char * enc,unsigned char* dec) {
int i=0,j=0;
for(i=0;i<40;i+=4) {
dec[j] = ((enc[i]-59)<<2)&0xfc | (((enc[i+2]-59)>>4))&3;
dec[j+1] = (((enc[i+2]-59)&0xf)<<4) | (((enc[i+1]-59)>>2)&0xf);
dec[j+2] = (((enc[i+1]-59)&3)<<6) | ((enc[i+3]-59)&0x3f);
j+=3;
}
dec[j] = ((enc[i]-59)<<2)&0xfc | (((enc[i+1]-59)>>4))&3;
dec[j+1] = (((enc[i+2]-59)>>2)&0xf) | (((enc[i+1]-59)<<4)&0xf0);
dec[j+2]=0;
}
void Rc4_Init(char *key,int len) {
int i=0,v5=0;
unsigned char temp;
for(i=0;i<256;i++) {
s[i] =i;
t[i] = key[i%len];
}
for(i=0;i<256;i++) {
v5=(s[i]+t[i]+v5)%256;
temp = s[i];
s[i]= s[v5];
s[v5]=temp;
}
}
void Rc4_dec1(int len, unsigned char *enc) {
int v3=0,v5=0,i,j;
unsigned char temp;
for(i=0;i<len;i++) {
v3=(v3+1)%256;
v5=(s[v3]+v5)%256;
temp=s[v3];
s[v3]=s[v5];
s[v5]=temp;
}
v5=v3=0;
for(i=0;i<len;i++) {
v3=(v3+1)%256;
v5 = (s[v3]+v5)%256;
temp = s[v3];
s[v3]=s[v5];
s[v5]=temp;
enc[i]^=s[(s[v5]+s[v3])%256]^0x59;
}
}
void Rc4_dec2(int len, unsigned char *enc) {
int v3=0,v5=0,i,j;
unsigned char temp;
v5=v3=0;
for(i=0;i<len;i++) {
v3=(v3+1)%256;
v5 = (s[v3]+v5)%256;
temp = s[v3];
s[v3]=s[v5];
s[v5]=temp;
enc[i]^=s[(s[v5]+s[v3])%256]^0x59;
}
}
flag{Hacking_for_fun@reverser$!}
通过这么一道CTF题目,深入学习LLVM IR的冰山一角,认真实验,细细分析,相信会对你有极大帮助。当然,如果单从解题来说,对于解决这道题有很多的办法,比如说将.II转化为可执行文件,然后IDA分析,但我们旨在学习LLVM IR,这里不再过多赘述。


